

 0
0
CHECK POINTING
Checkpointing process is one of the vital concept/activity under Hadoop. The Name node stores the metadata information in its hard disk.
We all know that metadata is the heart core of the distributed file system; if it is lost, we cannot access any files inside the file system.
The metadata physically gets stored in the machine in the form of two files
1. FSIMAGE - Snapshot of the file system at a point of time
2. EDITS FILE - Contains every transaction (creation,deletion,moving,renaming,copying ..etc of files) in the file system.
Based on HA(High Availability) in Hadoop V2, the backup of the NN's metadata will be stored in another machine called SNN(StandBy Name Node). Since different clients very frequently access metadata for reading other files, instead of keeping it in the hard disk, it is good to store it in the RAM, so that it can be accessed faster.
But Stop...What happens if the machine goes down. :(. We will lose everything in the RAM. Hence taking a backup of the data stored in the RAM is a viable option.

FSIMAGE0 -- Represents the fsimage file at a particular time
FSIMAGE1 -- Represents the copy of the FSIMAGE0 file, taken as a backup.
Let's imagine the backup of the file has to be taken for every 6 hours if something goes wrong in the cluster, and the machine gets down before taking the backup, i.e. before 6 hours, then we end up in losing the latest fsimage file.
So to overcome this problem, a new system has to be exclusively added in the cluster for doing the process of safeguarding the metadata efficiently, and that process is called CheckPointing Process.
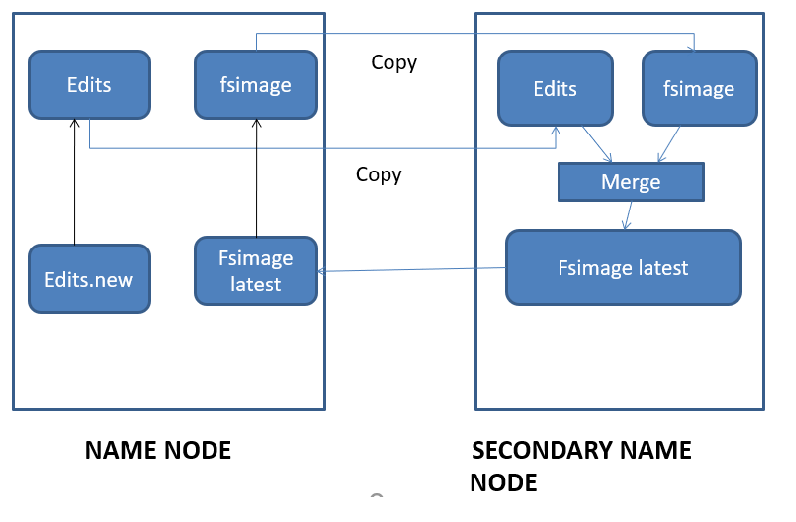
Please have a look at the picture and let's understand the process step by step.
STEP 1
A copy of the Metadata(Fsimage and Edits file) from NameNode will be taken and placed inside the Secondary name node(SNN).
STEP 2
Once the copy is placed in SNN, the Edits file which captures every single transaction happening in the file system will be merged with the fsimage file (Snapshot of the filesystem). The combined result will give the updated or latest file system.
STEP 3
The latest merged Fsimage will be moved to the NN's metadata location.
STEP 4
During the process of merging also, some of the files may be deleted or created or copied some transactions could have happened and those details will be stored in a new file called Edits.new, because the original Edits file has been opened/utilized for copying into the SNN, remember the deadlock principle.
STEP 5
Now the Edits.new file will become the latest Edits file, and the Merged fsimage will become the original fsimage file. This process will be continued for a specific interval.
So, now no more backup's are needed to save the metadata in NN in case of failover scenarios.
Will see more details and programs in the upcoming lessons.
Thank you!!


